Introduction
Le principe de la classification hiérarchique ascendante est de rassembler des individus selon un critère de ressemblance défini au préalable qui s’exprimera sous la forme d’une matrice de distances, exprimant la distance existante entre chaque couple d’individus. Deux observations identiques auront une distance nulle. Plus les deux observations seront dissemblables, plus la distance sera importante.
L'algorithme va ensuite rassembler les individus de manière itérative afin de produire un dendrogramme ou arbre de classification. La classification est ascendante car elle part des observations individuelles ; elle est hiérarchique car elle produit des classes ou groupes de plus en plus vastes, incluant des sous- groupes en leur sein. En découpant cet arbre à une certaine hauteur choisie, on produira la partition désirée.
Fonctionnement étape par étape
Voici un petit résumé du fonctionnement de l'algorithme classification hiérarchie ascendante: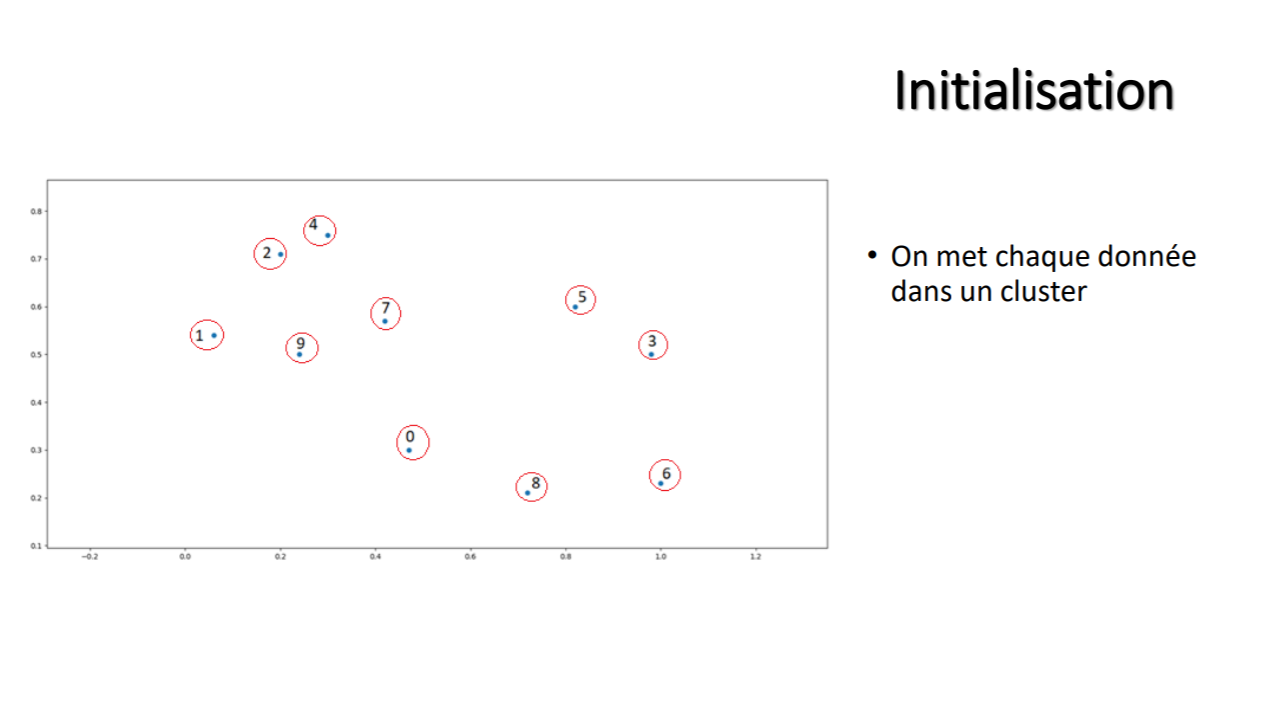
Jupyter
Le fichier Jupyter va te permettre de tester tes connaissances sur le fonctionnement de l'algorithme.
Il y a des parties à compléter sur les points clés de l'algorithme pour mieux comprendre son
fonctionnement.
Cela te permettra en même temps de faire le code (en Python) de l'algorithme, ce qui peut être utile si tu en as
besoin pour la suite.
![]()
Télécharger le fichier jupyter !
Comment utiliser un fichier Jupyter ?
Les fichiers Jupyters sont des fichiers qui permettent de créer un environnement Python, avec un affichage simple mêlant du texte et du code. C'est le support parfait pour comprendre clairement un code Python, et c'est la solution que nous avons choisi. Pour l'installer, rien de plus simple !- Téléchargez le fichier Jupyter ci-dessous
- Ouvrez votre Drive Google
- Téléversez ce fichier Jupyter dans votre Drive
- Pour l'ouvrir, faites clic droit, "ouvrir avec ...", "Colaboratory"
- Si vous n'avez pas cette option, faites "Connect More Apps" et cherchez "Colaboratory".Vous pourrez normalement faire l'étape précédente.
Fiche résumé
Bravo !
Tu as fini ce tutoriel sur le Regroupement Hiérarchique.
A ce stade, tu dois avoir compris le fonctionnement de l'algorithme, ce n'est maintenant plus une boite noire
pour toi !
Néanmoins, si jamais il te venait à oublier certains détails, voici une fiche résumé qui te rafraichira la
mémoire !
Télécharger la fiche résumé !