
Explorez vos données avec des algorithmes non supervisés
Utilisez les fichiers Jupyter pour consolider vos connaissances
Enregistez les fiches résumé pour être garantis de tout garder en tête
Introduction
La classification (clustering) est une méthode mathématique d’analyse de données qui
permet de prédire des classes de données : pour
faciliter l’étude d’une population d’effectif important (animaux, plantes, malades, gènes, etc.),
on les partitionne en plusieurs classes ou clusters (non
définis à l'avance) de telle sorte que les individus d’une même classe soient les
plus similaires possible et que les classes soient les plus distinctes
possibles.
Les algorithmes de clustering dépendent donc fortement de la façon dont on définit cette notion de
similarité, qui est souvent spécifique au domaine d'application.
En général, nous pouvons parler de classification automatique si aucune information n’est disponible concernant
l’appartenance de certaines données à certaines classes connues a priori.
Par ailleurs, le nombre de groupes recherchés peut être connu a priori ou non.
Il y a diverses façons de procéder qui peuvent conduire à des résultats différents. Dans ce cours nous présentons trois algorithmes : un premier appelé k-means (méthode des centres mobiles), un deuxième appelé classification hiérarchique ascendante et un troisième appelé DBSCAN.
Ces données ou individus seront représentés par des points. En effet, on peut représenter chaque individu par
une liste de caractéristiques dans un espace donné nous permet d'obtenir des vecteurs.
Pour certains algorithmes, il peut être utile d'avoir des données labellisées, c'est à dire
déjà classifiées, pour entraîner l'algorithme.
Ces données (petits échantillons généralement) sont généralement classifiées par des humains, et l'algorithme
tentera de reproduire ces décisions.
Les algorithmes de clustering :
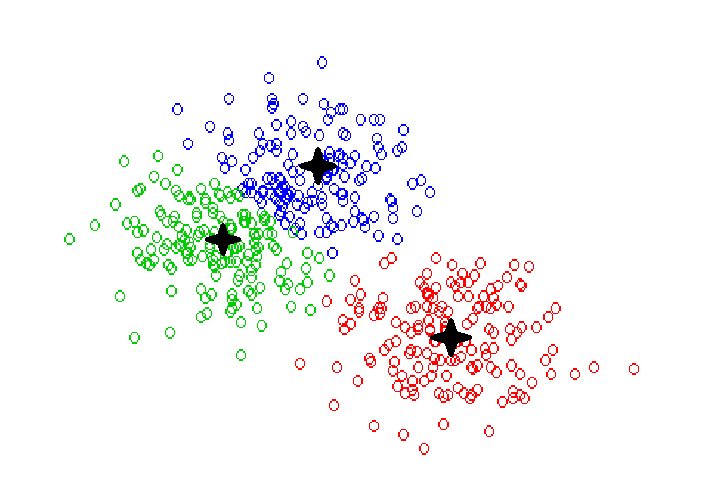
K-means
Le but de cet algorithme est d’identifier un certain nombre k de points répresentatifs des clusters, auxquels sont ensuite associés les autres points, selon leur proximité avec les points representatifs considérés.
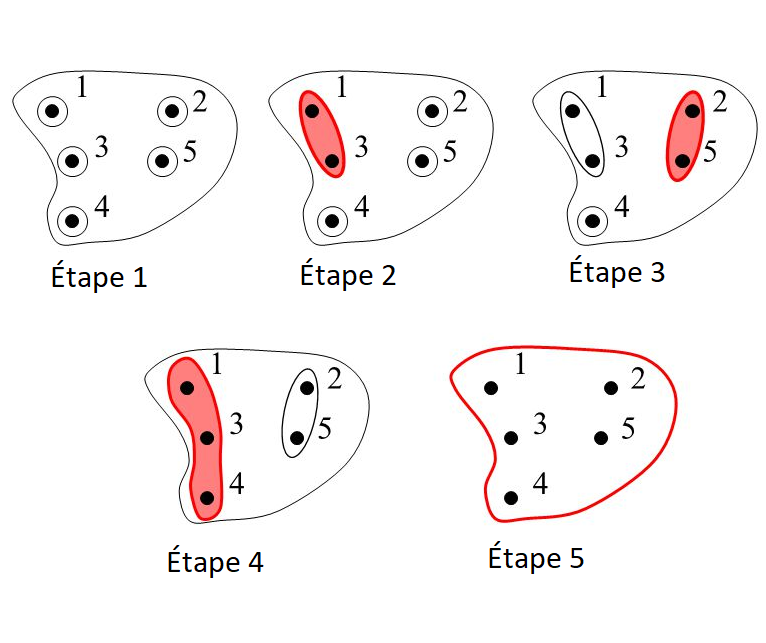
Classification hiérarchique ascendante
Le but de cet algorithme est de former une hiérarchie de clusters, telle que plus on descend dans la hiérarchie, plus les clusters sont spécifiques à un certain nombre d’objets considérés comme similaires.
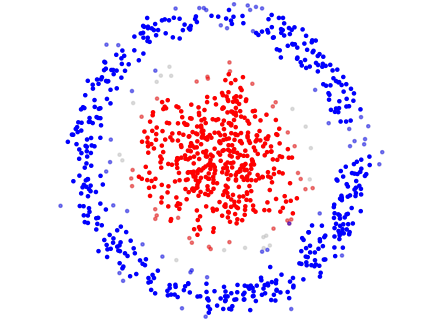
DBSCAN
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) a pour but d’identifier, dans l’espace, les zones de forte densité entourées par des zones de faible densité, qui formeront les clusters.
Mots-clés:
- Clustering : Méthode mathématique d’analyse de données qui consiste à partitionner en clusters/classes les données par groupe de similarité.
- Algorithme supervisé : Algorithme qui apprend de manière automatique à prédire un résultat et dont la phase d'apprentissage nécessite des données annotées (labelisées).
- Algorithme non-supervisé : Algorithme qui n'a pas besoin de données annotés lors de la phase d'apprentissage.